Spark数据流概述
Spark Streaming 简介,Spark API 核心的扩展。
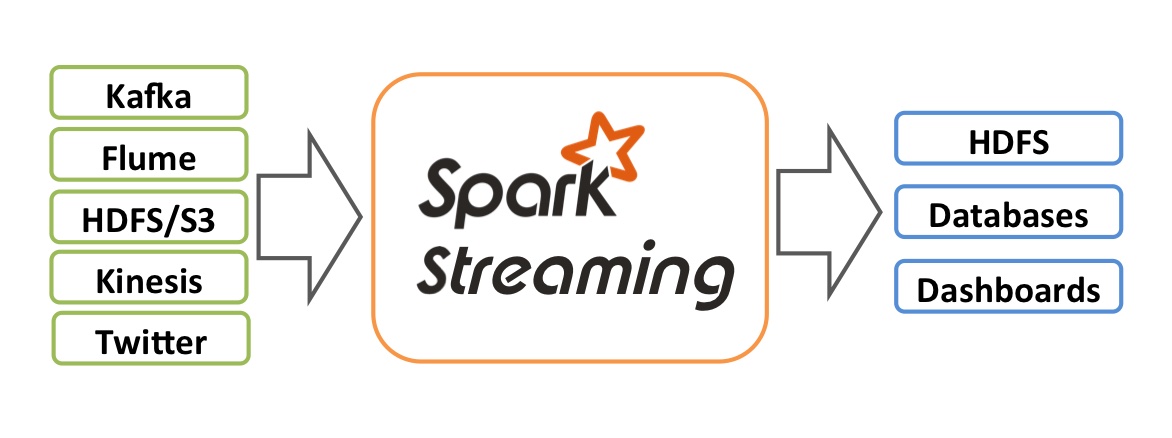
作为 Spark 核心 API 的扩展,Spark Streaming 从 Kafka、TCP 套接字甚至 Twitter 数据流等来源获取输入,使用 map、flatmap、filter 和 reduceByKey 等函数处理数据,最后将处理后的数据输出到 HDFS(Hadoop 分布式文件系统)、数据库或仪表盘等地方。Spark 本身适合一次性批量处理,以获得一次性答案或周期性答案,而 Spark Streaming 则不同,它允许您以接近实时的方式实现大规模数据处理。也就是说,您可以分析每次一小部分(如每分钟)涌入的海量数据,并在更多数据涌入时继续汇总结果。因此,当您需要进行这种计算时,不妨考虑 Spark Streaming。
Spark Streaming 的突出特点是可扩展、高穿透性和容错性。使 Spark Streaming 能够实现这一目标的一个关键组件是一个不可变的分布式数据集的高级抽象,称为 DStream(或离散流)。DStream 在内部表示为 RDD 的序列。使用 DStream,Spark Streaming 可以运行一系列小型的确定性批处理作业,然后分批输出结果。这就将每个批处理视为一个 RDD,并允许 Spark Streaming 对每个批处理执行 RDD 操作。在 DStream 上调用的 RDD 操作会转化为对按时间离散的底层 RDD 的操作。此外,还有一种foreach 转换,可以在最终输出前对每批结果进行处理。
批量大小按时间量化,如半秒或一秒。由于 Spark Streaming 在 RDD 上工作,因此有可能在一个系统中结合批处理和流式处理。除了标准的 RDD 操作(如 map、countByValue、reduce 和 join),Spark Streaming 还可以执行有状态的操作,因此某些信息会随着时间的推移而持续存在。
Spark 对 S3 和 HDFS 等容错文件系统中的数据进行操作,因此 Spark 生成的所有 RDD 也都是容错的。但 Spark Streaming 的情况并非如此,因为在使用 Spark Streaming 时,数据流通常是通过网络接收的,而且通常无法保证发送方使用容错文件系统。因此,需要另一种机制: Spark Streaming 会在集群的工作节点中复制接收到的数据。当发生故障时,如果数据已经收到并被复制,由于数据存在于另一个工作节点中,这些数据会在单个工作节点发生故障时存活下来。但是,如果数据已被接收但未被复制,那么就需要重新从数据源获取数据。
Spark Streaming 是一个非常有用的框架,因为它可以扩展到大型集群,在 100 个节点上以亚秒级的延迟实现高性能指标(可以每秒处理 6GB 的数据),具有简单而熟悉的编程模型,可以与批处理和交互式工作负载很好地集成,并且可以确定高效的容错有状态计算。