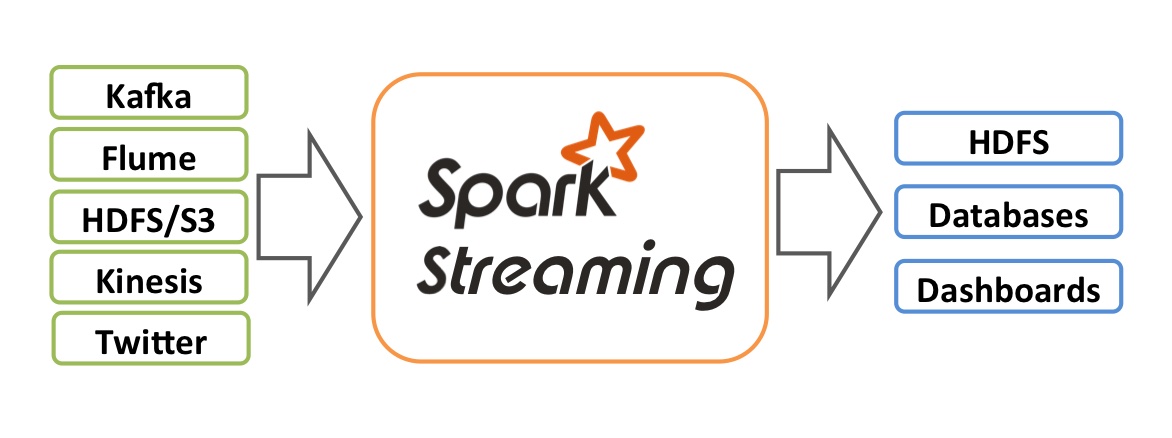
SPARK数据流概述
Spark Streaming 简介,Spark API 核心的扩展。 作为 Spark 核心 API 的扩展,Spark Streaming 从 Kafka、TCP 套接字甚至 Twitter 数据流等来源获取输入,使用 map、flatmap、filter 和 reduceByKey 等函数处理数据,最后将处理后的数据输出到 HDFS(Hadoop 分布式文件系统)、数据库或仪表盘等地方。Spark 本身适合一次性批量处理,以获得一次性答案或周期性答案,而 Spark Streaming 则不同,它允许您以接近实时的方式实现大规模数据处理。也就是说,您可以分析每次一小部分(如每分钟)涌入的海量数据,并在更多数据涌入时继续汇总结果。因此,当您需要进行这种计算时,不妨考虑 Spark Streaming。

编程语言学习笔记
我在2021年秋季PL(编程语言)期末考试前学习的笔记。 堆管理/垃圾回收 1. 引用计数器(快速方法) 在每个单元格中维护一个计数器,存储当前指向该单元格的指针数 指向该单元格的指针数 当计数器下降到 0 时,回收单元格 2.

康德在《序言》中对休谟的回应
我将首先介绍休谟关于因果关系不可能性的论证。然后,我将解释康德的先验判断证明如何旨在克服休谟的这种怀疑论。于2020年12月12日为PHIL 2103提交。 如果因果性(Causality)像休谟怀疑的那样是人类认知里永远无法获得的,那么形而上学(Metaphysics)将面临巨大压力。因为没有因果性,形而上学中的知识就不会延伸。而对于康德来说,知识延伸才是我们学习形而上学中“正确而恰当的研究对象”(our “proper object in studying it”)(273)。在《任何未来形而上学的序言》中,康德致力于拯救形而上学作为一门科学,通过拯救纯粹理解的概念,比如因果性。在本文中,我首先将呈现休谟对因果性不可能性的论证。然后,我将提出康德为克服休谟的怀疑所做的努力,证明“合成先验判断(synthetic a priori judgments)”的可能性。

JUDICIAL REVIEW: A NECESSARY MEANS OF COUNTER-MAJORITARIANISM
Written for PSCI 1111 at Vanderbilt University on October 1, 2019.