Thoughts on MapReduce
Overview and a bit of relection on the Google MapReduce paper.
While computations that process large amounts of raw data at Google are usually “conceptually straightforward,” the code needed to deal with the parallelizing computation, distribution, fault tolerance, and load balancing of large datasets are complicated and thus error-prone. In “MapReduce: Simplified Data Processing on Large Clusters,” researchers at Google tackle this complexity by proposing an abstraction that is “MapReduce,” which is inspired by functional programming concepts to automatically parallelize and distribute large-scale, high-performance computations.
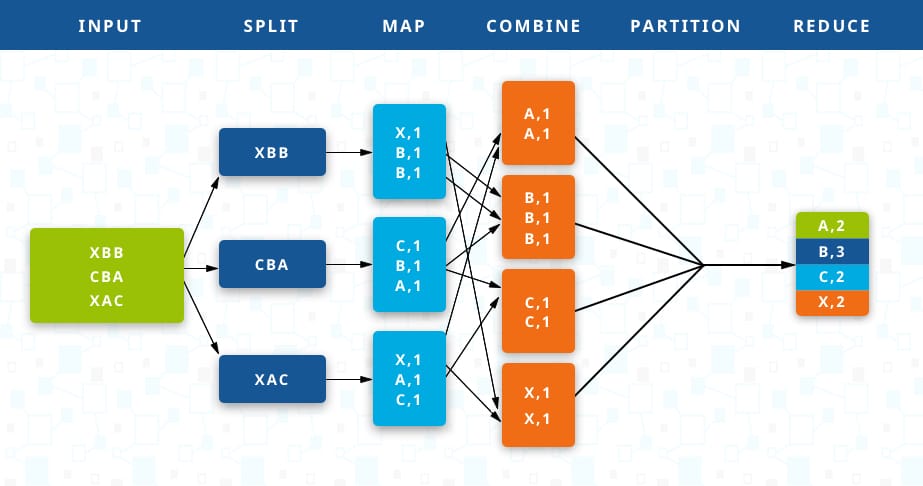
Fundamentally, the user implements the Map function, which generates an intermediate set of kv pairs
[map(k1,v1)->list(k2,v2)],
and the Reduce function
[reduce(k2,list(v2))->list(v2)],
which accepts the set produced by Map as an iterator and reduces the output to a smaller set. More specifically, a master program assigns an idle worker either a map task (input files are split into M pieces) that buff generated kv pairs ino memory, or a reduce task that receives the location of R regions of buffed kv pairs, sort and group all occurrences of the same keys together, then output the result for this particular partition. After all map and reduce tasks are done, control is returned back to the caller. The master program has data structures to store the state and identity of worker machines, making possible task distribution and critical information storage including location and size of intermediate file regions.
A worker is marked as failed if it does not respond in a set amount of time. When a completed map task fails, it is re-executed, since its results are stored locally. A failed, completed reduce task is not re-executed, since its results are stored in a global file system. Unreachable worker tasks are executed by the master, eventually completing the tasks. However, if the master fails, the paper’s implementation of MapReduce aborts the computation; the user can choose to try again. Another way is to replicate master. Additionally, the programmer may choose to save input files locally to minimize usage of network bandwidth, take practical bounds like how large M and R should be, and fight “stragglers” by scheduling backup executions.
The researchers also highlight several extensions that boost the MapReduce library’s usefulness. We may partition data by a function of the key instead of just the key to achieve the desired number of files or, for instance, to direct related outputs to the same file. We can also utilize partition-wide sorting, combiner function for partial merging before the intermediate kv pairs are sent to the reduce tasks, specify input and output types, omit data that prevent deterministic outcomes, execute MapReduce code locally for debugging as well as profiling and smaller-scale testing, user-friendly status page, and create counter objects for sanity checks. In actual testing, researchers found that not using backup executions and machine failures significantly increased elapsed time. In real life, the MapReduce library is shown helpful in large-scale ML processing and graph problems, clustering problems, as well as data and web page properties extraction.
A practical problem that can be efficiently solved by MapReduce is to find the frequency of a certain keyword in all pages under the same URL. Although MapReduce is a great step forward in terms of performance, I would assume that because more workers are used, theoretically speaking there could be more points of vulnerability. Another challenge is that MapReduce still needs a significant amount of storage, although they may be distributed.