Spark Streaming Overview
A brief overview of Spark Streaming, an extension of the core Spark API.
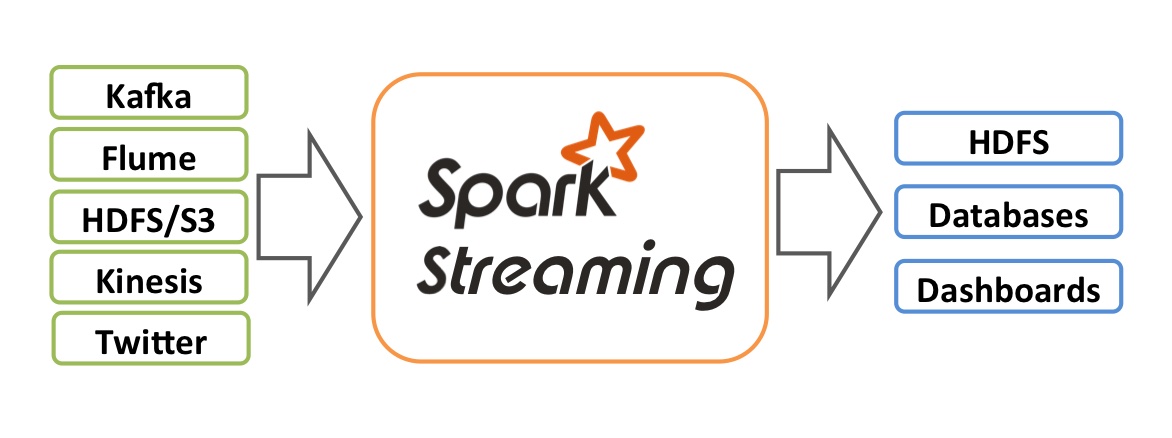
An extension of the core Spark API, Spark Streaming takes input from sources like Kafka, TCP sockets, or even Twitter streams, process data using functions like map, flatmap, filter, and reduceByKey, and finally output processed data to places like HDFS (Hadoop Distributed File System), databases, or dashboards. Unlike Spark itself, which is good for batch processing in one fell swoop to get a one-time answer or periodic answers, Spark Streaming allows you to achieve large-scale data processing in near-real-time. That is, you can analyze huge amounts of data as they come in one little section at a time (such as every minute) and continue aggregating results as more data comes in. So when you need this kind of computation, you may want to consider Spark Streaming.
Spark Streaming is highlighted as being scalable, high-throughout, and fault-tolerant. A key component which enables Spark Streaming to accomplish that is a high-level abstraction of an immutable and distributed dataset called DStream, or discretized stream. A DStream is internally represented as a sequence of RDDs. Using DStream, Spark Streaming runs a series of small, deterministic batch jobs and then outputs the results in batches. This treats each batch as an RDD and allows Spark Streaming to perform RDD operations of each of them. RDD operations called on the DStream are translated into operations on the underlying RDD discretized by time. There is also a foreach transformation which makes it possible to do something to each batch of results before the final output.
The batch sizes are quantized by time, such as half a second or one second. Because Spark Streaming works on RDDs, there is potential to combine batch processing and streaming processing in one system. In addition to standard RDD operations like map, countByValue, reduce, and join, Spark Streaming can also execute stateful operations so certain information persists over time.
Spark operates on data in fault-tolerant file systems including S3 and HDFS, so all the RDDs generated from Spark are also fault-tolerant. Such is not the case for Spark Streaming, since when using Spark Streaming the data stream is oftentimes received over the network, and more often than not you cannot guarantee the sender to use fault-tolerant file systems. As such, another mechanism is in place: Spark Streaming replicates data received in the cluster’s worker nodes. When a failure occurs, if the data has been received and has been replicated, because the data exists in another worker node, this data survives the single worker node failure. But if the data has been received but has not been replicated, then the data needs to be fetched again from the source.
Spark Streaming is a useful framework as it is scalable to large clusters, achieves high performance metrics (can process 6GB/sec) of data on 100 nodes at sub-second latency, has a simple and familiar programming model, integrates well with batch & interactive workloads, and can ascertain efficient fault-tolerant stateful computations.